You Know Your AI Adoption Rate. Do You Know Your Governance Rate?
Ask any engineering leader for their AI adoption rate, and the answer comes back fast. Seat counts, license tiers, daily active usage, the percentage of devs running Cursor or Copilot, and the latest productivity scores from the analytics dashboard. The data is clean and ready for the next board update.
Now ask for their governance rate. How much AI-generated code is sitting in production right now, who reviewed it, whether it followed component standards, and what changed between the prompt and the merge. The answer usually trails off into something polite about good intentions and an evolving review process.
That asymmetry is the thing worth paying attention to. Adoption is easy to measure because it has clean numbers attached to it. Control is harder to measure because the infrastructure needed to produce those measurements doesn't yet exist in enterprise AI tooling. So adoption metrics get reported up the chain as evidence that the AI strategy is working, and the harder question gets pushed to next quarter.
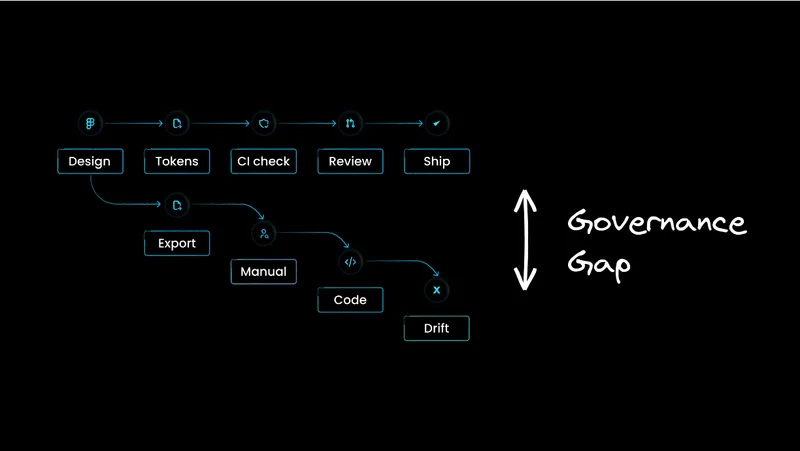
That deferral has a name. It's the governance gap, and it's getting wider as AI tooling expands beyond a few early-adopter developers into broader product teams. The cost of leaving it open isn't just risk in the traditional compliance sense, though that's part of it. The higher cost is that teams without governance infrastructure end up restricting AI use to protect themselves, thereby capping the productivity gains that justified buying the tools in the first place. It's the same dynamic behind the quality debt agent productivity creates when generation outpaces the systems that govern it.
The teams getting the most out of AI right now are the ones that built the infrastructure to trust what AI produces, which lets them run AI with less friction across more of the organization. The teams that skipped governance are quietly capping their own upside without realizing it, and it shows up in the backlog problem AI didn't solve at the org-wide delivery level.
Get our guide on the governance gap. It covers how the gap opened, the four questions every framework needs to answer, what distributed review looks like in practice, and the compliance dimension for regulated industries.
The adoption story at most enterprises followed the same arc. A handful of engineers started using AI coding assistants in their local environments. Output quality was uneven early on, but the productivity gains were real enough that usage spread by word of mouth, mostly without formal approval. By the time IT or engineering leadership noticed, the tools were already embedded in how a meaningful chunk of the team worked.
Leadership response usually broke one of two ways. Some organizations endorsed retroactively, which meant buying enterprise licenses, adding the tools to the approved list, and calling the question resolved. Others restricted retroactively, banning unapproved tools and issuing a usage policy. Neither response touched the underlying question of what was actually being produced and merged into production.
The enterprise license response is the more common path, and it creates a sense of resolution that feels useful. The organization now has visibility into seat usage, a real contract with a vendor, and an AI tool on the official approved list. The harder question of whether the code these tools generate meets organizational standards, follows the architecture, uses approved components, and receives meaningful review before it ships remains open.

The restriction response fares no better in practice. Developers route around it, use tools on personal machines, and the code still gets merged with even less paper trail than the licensed alternative would have produced.
Both responses manage perception while the actual problem compounds beneath the surface.
The governance gap isn't one problem. It surfaces in a few distinct ways across an enterprise, and most organizations are dealing with all of them at once without recognizing them as related.
| Where the gap opens | What it looks like | Why is it hard to catch |
Design system drift | AI-generated code uses generic components, hard-coded values, and one-off variants instead of your real system | Output renders correctly and passes linting, so reviewers approve it |
Review processes built for human authorship | PR volume from parallel agents runs an order of magnitude higher than review capacity | The infrastructure assumes one author, one branch, one session at a time |
Expanded authorship | PMs, designers, QA, and marketing now generate production code through different tools and workflows | Governance was designed when developers were the only ones writing code |
Design system drift
The most visible symptom is design system drift. AI tools that generate code without access to your actual component library produce output that looks correct on the surface but quietly diverges from the system your design team maintains. Generic implementations replace approved components. Hard-coded values show up where design tokens should be. New variants are created when an existing one would have worked. The code passes review because it works, renders correctly, and passes linting, so nobody flags it.

Each merged component that bypasses the design system sets a precedent. The reviewer who approved the first one set a bar, and the next engineer reviewing similar output implicitly has permission to merge it the same way. Over enough cycles, the design system becomes less authoritative, and nobody made an explicit decision to abandon it. The tooling simply stopped enforcing it.
Review processes built for a different era of authorship
The second place the gap shows up is in review processes that were built for a different era of authorship. Traditional code review assumes a human author with stakes in the outcome, institutional memory of why certain decisions were made, and accountability for the change. AI-generated code disrupts each of those assumptions. The author is an agent with no stake in the outcome; the context lives in a prompt that nobody else saw; and the scope can be large enough to generate a full-page layout or a set of API integrations in seconds.
The volume problem compounds the reasoning problem. Single-agent AI development is manageable with existing infrastructure because a single developer running a single session on a single branch lands in the review queue alongside everything else. Multi-agent parallel development breaks this entirely. When a team is running ten agents simultaneously, one per ticket and each on its own branch, the PR volume runs an order of magnitude higher than the review capacity. Engineering becomes the bottleneck because generation throughput outpaced review throughput, regardless of how quickly the reviewers work.
Expanded authorship, unchanged governance
The third place the gap opens up is the one most organizations haven't fully reckoned with yet. For the first few years of AI coding tool adoption, governance was primarily an engineering question because developers were the ones generating code. That framing is becoming less accurate every quarter. Product managers are building working prototypes in production codebases. Designers are submitting PRs from visual editors with AI handling the code translation. QA teams are generating fixes for the bugs they find. Marketing teams are publishing pages through systems that access the same component libraries engineers maintain. The whole code-as-canvas shift is real, and it's expanding the governance surface faster than most enterprises have planned for.
This expansion is broadly a good thing and turns AI development into the company-wide workflow change it was always supposed to be. It also creates a governance surface that's much larger and more varied than what enterprise security and engineering teams originally designed for. The developers using Cursor went through onboarding, know the codebase, and understand when to follow conventions and when to escalate. The PM who generated a prototype in a production branch last week may not know that the component they used has a deprecated variant or that the API they called has a rate limit nobody documented.
When organizations do address the governance gap, they usually frame it as a risk problem. That framing captures part of the picture. The downside costs are real: security vulnerabilities that survive review because the reviewer assumed AI-generated code had been checked, design system fragmentation that makes future UI work harder, technical debt that accumulates in AI-generated output that nobody owns, and compliance exposure in regulated industries where AI-generated code may not meet documentation requirements for production systems.
These costs matter, and for most organizations, they haven't yet materialized catastrophically, which is part of why the gap persists. The debt is accumulating quietly.
The opportunity cost is less visible and probably larger. Teams that don't trust AI-generated output restrict its use, require extra review cycles, and limit which roles can generate code and what it can touch. These are rational responses to an absence of control infrastructure, and they cap the productivity gains that motivated AI adoption in the first place. The organizations getting the largest gains from enterprise AI development are running the playbook in reverse: build the governance infrastructure first so AI can run with less friction across more of the team and more of the codebase.
Closing the governance gap is infrastructure work, not policy work. Documenting that designers should review AI-generated UI before it merges is a policy. Building a workflow that requires designer review before a PR can even be opened is governance. The full picture across context, review, traceability, and volume is what we walked through in the new guide.
A few things worth previewing:
- Design system enforcement can't happen at the review stage if the AI generating the code never had access to the current design system in the first place. The governance work starts upstream, with accurate context as an input to generation.
- Single-queue PR review breaks down as a governance mechanism when you run multiple agents in parallel. The teams scaling AI development well are distributing reviews across roles: designers validating visual output, QA validating correctness, and product validating requirements before a PR reaches engineering. Engineers receive work that has already passed domain-specific checks, allowing the engineering review to focus on code quality rather than functional correctness from scratch.

For organizations in regulated industries, the audit trail problem is sharper than most legal and compliance teams have recognized. Current AI tooling does not produce the generation records that may eventually be required by change control. The organizations not thinking about this now will be retrofitting it later under worse conditions.
Builder is the AI product development platform built for teams that need to govern what AI produces. It connects to your real codebase and design system, enforces standards before generation happens, and gives every role on your team the access they need to review and contribute without creating a new governance gap in the process.
Design system context is a first-class input to every generation. Review workflows are multi-role by default. Every agent runs in an isolated environment with a shareable preview, and agent work stays visible at the team level, so the people accountable for what ships can see what's in flight.