Developer experience is dead. Long live agent experience.

For the past ten years, we've obsessed over the developer feedback loop.
We didn’t do this just to make local setups feel fast (though that was always a nice side effect). We did it because friction is the enemy of momentum. Developers don't write great software through sheer willpower; they write it when the system around them makes the right path the easy path.
Good developer experience (DX) assumes people are tired, that they skipped the migration guide, and that they're one cat-on-the-keyboard away from taking down prod. It wraps you in fast, deterministic safety nets—compilers, linters, hot reloading, and branch previews—so you can focus on building.
Lately, we've been inviting a new kind of contributor to our repos: AI agents. But for some reason, we've been treating them like wizards instead of the completely stateless tools they are.
An agent has no lived memory of your product. It doesn't know about the legacy bugs your team learned to fear, and it has no tribal knowledge of your codebase. Left to its own devices, a stateless agent will walk directly into the same architectural wall five times in a row unless the system around it provides a better feedback loop.
If coding agents are going to do meaningful work in real-world codebases, we have to stop only optimizing our prompts and start actively engineering their environments. We need to transition from developer experience to agent experience (AX).
Agent experience is the discipline of designing the layer between a model and a real codebase: the context, tools, permissions, tests, and review loops that tell the agent what matters, what it can touch, and how it knows it worked.

It’s about a simple, first-principles question: How do we build a fast, secure, and deterministic feedback loop for agents?
From there, we have seven core tenets.
Developer onboarding used to be a seasonal event: how quickly can a new human understand this repo and make a safe first contribution?
With agents, onboarding happens at the start of every single task. Repository instructions, setup commands, component APIs, schemas, and known failure modes shape what the agent sees, tries, ignores, and verifies.
The temptation, then, is to over-document. To make sure the agent has all the context it could ever need.
But left unchecked, teams accumulate a graveyard of skills, AGENTS.md rules, stale definitions, prompt snippets, and hidden tool instructions. In a world of too much context, when an agent makes a bad choice, the human reviewer has to debug a massive, non-deterministic input history to figure out which stale instruction or conflicting rule led the model astray.
Good agent context instead behaves like good code. It should be minimal, transparent, and tested.
- Minimal: Global context stays thin and, anywhere possible, points back to the code itself.
- Transparent: A reviewer can easily audit which rule, skill, or setup note shaped the work.
- Tested: Team skills are self-explanatory enough that the agent can invoke them at the right time, and the reviewer can understand why.
Agent rules, skills, and other context must be a team discipline rather than a pile of experiments.
We accept that large language models (LLMs) are inherently non-deterministic. Because their cognitive engine is probabilistic, the rest of their execution environment must be aggressively deterministic.
The environment is literally part of the prompt. Dependency versions, local scripts, environment-variable shapes, seed data, auth setups, browser access, and local services determine what the agent can observe and correct.
"I couldn't run the tests locally, but this should work" is a massive DX red flag when a human says it. When an agent does it, we tend to just hope for the best.
A human developer who hits a missing environment variable, a broken database seed step, or a cryptic Docker error will stop and investigate. An agent will route around the failure, change the wrong file, and ship a guess with a polite commit message. If the agent can't compile the code, run the dev server, seed the database, or hit a local API, its output is not trustworthy software.
Agents must have a reliable, consistent, observable workspace before its output can be trusted.
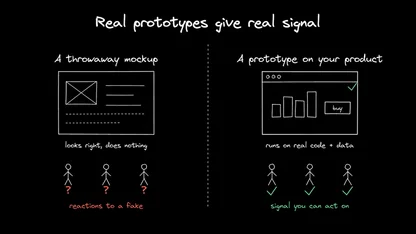
Agents shoudn't stop at generating code. They need to prove their work.
We're currently trading the friction of writing code for the exhausting cognitive load of reviewing it. If a you have to spend thirty minutes manually QA-ing an agentic PR, checking edge cases, and cleaning up generic layout styles, the agent didn't save you time. It just shifted the labor.
And when devs have too much review labor, quality slips drastically.
Good AX means the agent does more of that work before handoff. It's task, when complete, should present evidence: tests run, screenshots captured, browser flows checked, logs inspected, accessibility trees reviewed, and edge cases explored. Developers shouldn't have to rediscover all of that from scratch.

Typechecks, unit tests, and linting are still the bones of a serious workflow. But product work also fails where compilers are blind: responsive layouts that collapse, loading states that trap users, or broken flows that technically compile. Giving agents access to tools like Chrome DevTools MCP, Playwright, and automatic branch previews allows them to gather empirical evidence before handing off the work.
Spend tokens before spending reviewer attention. Tokens are cheap, pretty much unlimited, and run 24/7. Senior developer focus is precious, expensive, and burns out. If an agent can check its own work in a closed loop, it should.
And when the agent presents its work, the handoff should be as easy as possible to act on. A reviewer should be able to leave a visual note on a preview branch or point to a failed check and send that context back into the agent's execution loop, letting it self-correct in the workspace it already understands, rather than forcing a developer to copy-paste feedback across tools to restart the workflow.
Good DX made dangerous actions hard. Good AX needs to make dangerous actions impossible. Agents act quickly, literally, and at scale.
A prompt like, "Make sure not to mess with the database!" doesn't really help. Prompts are easily bypassed. Safety must be structural: sandboxing, scoped credentials, file and network limits, separate development and production data, environment-variable approval gates, and human-in-the-loop validation for high-risk actions.
Any time I see drama on Twitter where an agent dropped a database, I think, "Why did your system allow for that? Why did the agent have that access?"
The same bounded-environment principles apply as agents move beyond isolated developer terminals. If a PM, designer, or marketer uses an agent to iterate on a product surface, they shouldn't accidentally inherit root access to a local machine or production credentials. Safety shouldn't depend on whether a non-technical teammate understands what rm -rf, OAuth scopes, or production environment variables can do.
As agents move beyond developers, non-technical teammates will start using them to ship real changes. Safety can't depend on whether a PM or marketer understands what rm -rf , Oauth scopes, or production environment variables can do. The sandbox must be the absolute security boundary.
We spend too much time focusing on the weekly frontier model horse race, but the real questions for teams are:
- Who can access agents?
- Against what systems?
- With what context?
- Under what review process?
- Through which model route?
- And with what audit trail?
Model routing should be boring in the best possible way. Teams need provider flexibility and task-appropriate models, but every developer shouldn't have to become a model-selection expert just to get work done. Cheap, fast models can help with low-risk summarization, triage, classification, scaffolding, or routine review support. Deterministic syntax validation belongs to linters, typecheckers, and test runners. Expensive reasoning models should be reserved for harder multi-file judgment work.
Good governance belongs directly inside the agent path. Admins should see usage and costs, reviewers should see execution evidence, and teams should have the flexibility to switch providers without rewriting their entire application logic.
Your codebase isn't just for human maintainability anymore. For an agent to execute tasks reliably, the codebase must be the most accurate record of how the product actually works.
If your codebase is messy—if the docs say one thing, the components do another, and Storybook is three versions behind—the agent will synthesize that confusion into elegant-looking garbage.

To make your codebase ready for AI, you have to design it using classic software engineering principles: deep modules with thin public interfaces, typed APIs, predictable routing, and clean directory structures.
This is progressive disclosure for machines. By keeping implementation details hidden behind clean interfaces, we lower the cognitive load on the agent, which translates directly to lower token usage and fewer logic errors.
The same applies to design systems. The more your codebase forces the agent to reuse human-made components, tokens, and accessibility patterns, the less likely the output is to become generic sludge. The agent shouldn't be inventing a custom button when your team's button is right there.
Agent experience starts with developers, but it's actually an organizational coordination engine.
When agents make Version 1 of a feature cheap to generate, they don't solve Version 2, 3, or 4. Without a shared workspace, the developer becomes a high-priced human router who copies visual feedback from Slack, translates it back to the agent's prompt interface, runs the workspace locally, and manually manages the branch.
But the best AX moves away from pre-code abstractions toward shared iteration around live product surfaces.
With interactive preview deployments and role-aware controls, a designer, marketer, or PM can talk to the agent directly inside a safe, bounded preview. They can test responsive states, iterate on copy, or tweak layouts on a branch preview, while developers retain ownership over architecture, safety, and system integration. The developer is no longer the copy-paste bottleneck; they are the platform engineer who owns the system design.
You can certainly cobble these pieces together yourself: a coding agent extension, an isolated sandbox service, a rules file in one repo, a browser testing tool, a manual review workflow over Slack, etc.
But when you do that, the seams often become the work. You will likely find yourself spending more time maintaining your internal agentic infrastructure than shipping features.
At Builder, our bet is that agentic work becomes truly valuable when the whole team can collaborate on real code with shared context, deterministic environments, visual previews, governance, and a clear path back to human review.
By treating the codebase, the execution environment, and the team as a single collaborative workspace, we make it possible for agents to run tests, compile code, and generate visual branch previews automatically. It changes the interaction from a disconnected code-generation tool to a reliable, structural team contributor.
You can learn more about this philosophy by seeing how Fusion works or reaching out to one of our AX experts.
LLMs should do the glue work. People should do the interesting work.
If humans are copying feedback between tools, re-explaining repo context, manually checking whether the agent broke the obvious thing, policing stale docs, and cleaning up generic output while the model makes the creative decisions, the system is upside down.
Good agent experience gives creative people more room to use judgment, taste, architecture, strategy, care, and craft.
Developer experience became a discipline because we realized that software quality is a function of the systems we build. Agent experience will become a discipline for the exact same reason.
The point isn't to replace the people who understand the system. The point is to give them back the time to do the work only humans can do.