Data, Service, and Dependency Injection
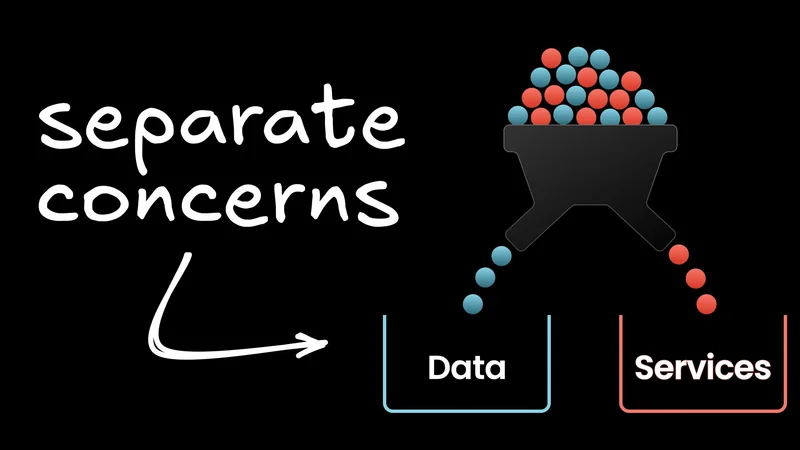
There are two kinds of classes in good OO design. Classes that represent data (value objects) and classes that represent services. Following the data vs services pattern will result in a better, more maintainable codebase. When constructing objects. Data should be just constructed, whereas services should be constructed through the dependency injection design pattern.
Data:
- Also known as: value objects, plain-old-data, value types.
- Value objects should store only data and should depend only on other value objects
Service:
- Also known as: service objects, business logic, controllers, orchestrators, behavior
- Services operate on value objects and contain the business logic.
- Because services depend on other services, the object graph should be constructed through the dependency-injection design pattern.
Let’s take an extreme example. Imagine that you have a String class representing a sentence in English. You want to have a translate() method which translates the text from English to French. I think it is obvious that the translate() method should not be part of a String class, since a String can represent many different things, not just something which is about to get translated.
A translation service needs to talk to an external API over the network, which does the translation. We would be mixing concerns if we made the String class know how to translate itself. The String class would have a reference to a network, auth, or other objects to enable a translate() method. Instead, we should have a Translator service which has a translate() method that takes a String in English and produces a new String in French. The Translator service internally has dependencies on network and auth to perform the translation over the network.
Here, String represents data, and the Translator represents a service that knows how to translate the data. From a compilation point of view, a String can be compiled independently of Translator. Data should not depend on Service.
Making an analogy to the real world, a piece of text (say, on paper) does not know how to translate itself. Instead, an external person/process knows how to consume an input string and produce a new output string. There can be many different kinds of translation mechanisms, and it should not be the String itself doing the translation.
What would happen if we move the translate() method into String? Translation requires external dependencies, such as network and auth. Moving translate() into String would mean that the String would now have properties which point to a network and auth. String would cease to be reusable. But more importantly, one would have to compile the network and auth before String can be compiled. This is highly undesirable and backwards. Here, network and auth are services, and data should not depend on services.
An important non-obvious property of data vs service objects is that the value objects can depend on other value objects. In contrast, services can depend on value objects or other services. When discussing dependency, we are discussing compile-time dependency. It should be possible to compile the String class without the Translation class. This should feel intuitive! String is a low-level concept, whereas Translation is a complex service that, in turn, may need many other Strings, for example, to define input and output language.
Strings by themselves are not enough to represent complex data. We use strings along with other primitives to build up more complex data structures. For example, an Address is a collection of strings such as street name, street number, city, zip, state, and country. An Address is also a value object since it is made up of (depends on) only other (String) value objects.
Let’s say we want to validate whether the zip code matches the entered city and state. One may be tempted to add a zipValidate() method to the Address, but this would be a mistake. Zip code validation needs to query a database of cities and their corresponding zip codes. This database is continuously updated as cities are incorporated. This means that the validation process likely depends on network and configuration information, which likely includes authentication credentials. An Address should not have a dependency on a network or auth credentials.
Going to a real-world analogy, an address (written on paper) cannot validate itself. Instead, an external person/service/post office knows how to consume the address and make a verdict if it is valid.
More importantly, there are many different ways in which someone could validate an address. Is the zip code valid? Is the street address valid? Is the address residential or commercial? And so on. The Address stores data and should not know how to validate itself, because validation requires talking to external systems. Having an Address contain validation logic would create an inverted dependency (i.e., Address depending on a database, rather than a database depending on an Address).
An Address can be used inside an Invoice, and again, we may be tempted to add pay(), fraudDetection(), accountingSummary(), or a myriad of other methods to the Invoice. In each case, doing so would invert the dependency and have a value object/data dependent on a service such as a payment processor, fraud detection, accounting systems, marketing analysis, and so on. If for no other reason, it would be a bad idea to mix so many different aspects of what one could do with an Invoice into a single class. And again, adding such methods would mean that the Invoice class would have to have fields pointing to these external services, such as network, database, etc. This would invert the compilation order of things. One should be able to compile Invoice independently of other dependencies.
Value objects can depend on other value objects. An Invoice depends on an Address, which in turn depends on a String. An Invoice depends on a Customer, Product, and so on, each a value object. Having value objects depend on other value objects is perfectly fine. It makes sense that one has to compile a String before one can compile an Address, and that Address needs to be compiled before Invoice. But it would be very strange if Invoice would depend on a database, fraud system, accounting, marketing, or a myriad of other services that consume Invoice.
Let’s talk about the ZipCodeValidator service from the previous example. Such a validator can consume an Address and extract the zip code, look up all of the cities, and verify that the city is one of the valid cities with the zip code. Where does the validator get information about which cities are associated with which zip codes? Presumably, there is a database. The database is updated periodically, so it should not be compiled into the codebase; instead, we need to talk to the database over the network. What about database credentials? Do we need to keep track of the number of queries we make per second? Are we getting charged for the queries? As you can see, this is a complex problem, and so the zipcode validator service is not a single class but a collection of classes, a network, a database connection, a logging service, and so on.
ZipCode validator is a graph of many different classes, each performing a different sub-function. This is a good thing because it breaks up a complex problem into more minor, simpler problems, and each problem is encapsulated into a separate class. But this encapsulation also allows us to create mock versions of the classes for testing purposes. How about a real validator class but with a mock database so that we can verify that the validator can correctly validate the address without relying on talking to a real database over the network, which would be a source of flakiness.
Services are a graph of other services. ZipCodeValidator depends on DBLogger to track and log requests, which in turn depends on the DatabaseConnector, which talks to the DB over the network. Each service does a small, specific task, and together they accomplish the main task.
It is tempting to make the ZipCodeValidator class create all of the dependencies in its constructor, but doing so means that only one type of graph can be created. Constructors fix your dependencies. In our case, it means that the ZipCodeValidator could only ever talk to an actual DB over a real network. The dependency graph is fixed! But for testing purposes, we want to create a different graph. One that points to a MockDB or a MockDBLogger, which points to an in-memory log rather than a log on disk, and so on. In essence, having the constructor create the graph in the constructor (inline) prevents us from creating alternate graphs, such as for testing. Therefore, creating your dependencies in the constructor should be avoided. Instead, the ZipCodeValidator should have its dependencies be passed into the constructor, allowing us to pass in mock or preconfigured versions of the dependencies for testing purposes. By asking for the dependencies (rather than instantiating the dependencies), we are now free to construct different graphs of services. By controlling the service graphs, we can control how information flows. This gives us better control over testing.
Drawing an analogy from real life, cars don’t build themselves. Car factories build cars. Car factories decide how the car is assembled, and car factories allow the creation of different options. The car does not decide if it is red, or if it has a premium stereo, or a 5-seat or 7-seat configuration. The car factories do. In the same vein, it should not be the constructor of the ZipCodeValidator to construct its dependencies. Instead, the dependencies should be passed in. Only when the dependencies are passed in can we create a mock graph for testing purposes.
Dependency injection simply says that a class should ask for its dependencies, rather than have the class constructor create the dependencies inline.
Depending on the graph we create, the codebase can do production work. Alternatively, nodes in the graph can be swapped out with mocks, fakes, or pre-wired answers. The ability to control the graph construction is what gives us the power to make tests in isolation. It is what allows us to create a ZipCodeValidator, which is hooked to a mock database that has prefilled entries and allows us to simulate corner cases quickly.
- Data is encapsulated, meaning it only depends on other data, not on external information.
- Working with external information should be handled by the services.
- Data depends only on other data.
- Services can depend on other services and data.
- Data can just be constructed; services should be constructed with dependency injection in mind.
- Dependency injection means that the services ask for other services in their constructors (rather than instantiating those services inline in the constructor).
Avoid:
- Having data depend on services inverts the order of compilation and is undesirable.
- If services instantiate their own dependencies, the dependency graph is fixed, and it makes it hard to create tests that mock out parts of the system.