Hydration is a solution to add interactivity to server-rendered HTML. This is how Wikipedia defines hydration:
In web development, hydration or rehydration is a technique in which client-side JavaScript converts a static HTML web page, delivered either through static hosting or server-side rendering, into a dynamic web page by attaching event handlers to the HTML elements.
The above definition talks about hydration in terms of attaching event handlers to the static HTML. However, attaching event handlers to the DOM is not the challenging or expensive part of the hydration, and so it misses the point of why anyone would call hydration an overhead. For this article, overhead is work that can be avoided and still leads to the same end result. If it can be removed and the result is the same, it is an overhead.
The hard part of hydration is knowing WHAT event handlers we need and WHERE they need to be attached.
WHAT: The event handler is a closure that contains the behavior of the event handler. It is what should happen if a user triggers this event.WHERE: The location of the DOM element where theWHATneeds to be attached to (includes the event type.)
The added complication is that WHAT is a closure that closes over APP_STATE and FRAMEWORK_STATE:
APP_STATE: the state of the application.APP_STATEis what most people think of as the state. WithoutAPP_STATE, your application has nothing dynamic to show to the user.FRAMEWORK_STATE: the internal state of the framework. WithoutFRAMEWORK_STATE, the framework does not know which DOM nodes to update or when the framework should update them. Examples are component-tree, and references to render functions.
So how do we recover WHAT (APP_STATE + FRAMEWORK_STATE) and WHERE? By downloading and executing the components currently in the HTML. The download and execution of rendered components in HTML is the expensive part.
In other words, hydration is a hack to recover the APP_STATE and FRAMEWORK_STATE by eagerly executing the app code in the browser and involves:
- downloading component code
- executing component code
- recovering the
WHAT(APP_STATEandFRAMEWORK_STATE) andWHEREto get event handler closure - attaching
WHAT(the event handler closure) toWHERE(a DOM element)
Let's call the first three steps the RECOVERY phase. RECOVERY is when the framework is trying to rebuild the application. The rebuild is expensive because it requires downloading and executing the application code.
RECOVERY is directly proportional to the complexity of the page being hydrated and can easily take 10 seconds on a mobile device. Since RECOVERY is the expensive part, most applications have a sub-optimal startup performance, especially on mobile.
RECOVERY is also pure overhead. Overhead is work done that does not directly provide value. In the context of hydration, RECOVERY is overhead because it rebuilds information that the server already gathered as part of SSR/SSG. Instead of sending the information to the client, the information was discarded. As a result, the client must perform expensive RECOVERY to rebuild what the server already had. If only the server had serialized the information and sent it to the client along with HTML, the RECOVERY could have been avoided. The serialized information would save the client from eagerly downloading and executing all of the components in the HTML.
The re-execution of code on the client that the server already executed as part of SSR/SSG is what makes hydration pure overhead: that is, a duplication of work by the client that the server already did. The framework could have avoided the cost by transferring information from the server to the client, but instead, it threw the information away.
In summary, hydration is recovering event handlers by downloading and re-executing all components in the SSR/SSG-rendered HTML. The site is sent to the client twice, once as HTML, and again as JavaScript. Additionally, the framework must eagerly execute the JavaScript to recover WHAT, WHERE, APP_STATE, and FRAMEWORK_STATE. All this work just to retrieve something the server already had but discarded!!
To appreciate why hydration forces duplication of work on the client, let's look at an example with a few simple components.
We'll use a popular syntax understood by many people, but keep in mind that this is a general problem not specific to any one framework.
The above will result in this HTML after the SSR/SSG:
The HTML carries no indication of where event handlers or component boundaries are. The resulting HTML does not contain WHAT(APP_STATE, FRAMEWORK_STATE) or WHERE. The information existed when the server generated the HTML, but the server did not serialize it. The only thing the client can do to make the application interactive is to recover the information by downloading and executing the code. We do this to recover the event handler closures that close over the state.
The point here is that the code must be downloaded and executed before any event handler can be attached and events processed. The code execution instantiates the components and recreates the state (WHAT(APP_STATE, FRAMEWORK_STATE) and WHERE).
Once hydration completes, the application can run. Clicking on the buttons will update the UI as expected.
So how do you design a system without hydration and therefore, without the overhead?
To remove overhead, the framework must not only avoid RECOVERY but also step four from above. Step four is attaching the WHAT to WHERE, and it's a cost that can be avoided.
To avoid this cost, you need three things:
- Serialize all of the required information as part of the HTML. The serialized information needs to include
WHAT,WHERE,APP_STATE, andFRAMEWORK_STATE. - A global event handler that relies on event bubbling to intercept all events. The event handler needs to be global so that we are not forced to eagerly register all events individually on specific DOM elements.
- A factory function that can lazily recover the event handler (the
WHAT).
A factory function is the key! Hydration creates the WHAT eagerly because it needs the WHAT to attach it to WHERE. Instead, we can avoid doing unnecessary work by creating the WHAT lazily as a response to a user event.
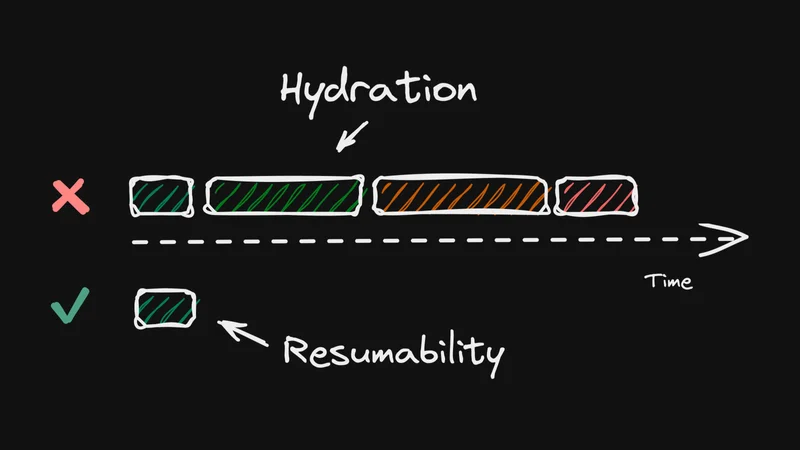
The above setup is resumable because it can resume the execution where the server left off without redoing any work that the server already did. More importantly, the setup has no overhead because all of the work is necessary and none of the work is redoing what the server already did.
A good way to think about the difference is by looking at push and pull systems.
- Push (hydration): Eagerly download and execute code to eagerly register the event handlers, just in case of user interaction.
- Pull (resumability): Do nothing, wait for a user to trigger an event, then lazily create the handler to process the event.
In hydration, the event handler creation happens before the event is triggered and is therefore eager. Hydration also requires that all possible event handlers be created and registered, just in case the user triggers the event (potentially unnecessary work). So event handler creation is speculative. It is extra work that may not be needed. (The event handler is also created by redoing the same work that the server has already done; hence it is overhead)
In a resumable system, the event handler creation is lazy. Therefore, the creation happens after the event is triggered and is strictly on an as-needed basis. The framework creates the event handler by deserializing it, and thus the client does not redo any work that the server already did.
The lazy creation of event handlers is how Qwik works, which allows it to create speedy application startup times.
Resumability requires that we serialize WHAT(APP_STATE, FRAMEWORK_STATE) and WHERE. A resumable system may generate the following HTML as a possible solution to store WHAT(APP_STATE, FRAMEWORK_STATE) and WHERE. The exact details are not important, only that all of the information is present.
When the above HTML loads in the browser, it will immediately execute the inlined script that sets up the global listener. The application is ready to accept events, but the browser has not executed any application code. This is as close to zero-JS as you can get.
The HTML contains the WHERE encoded as attributes on the element. When the user triggers an event, the framework can use the information in the DOM to lazily create the event handler. The creation involves the lazy deserializing ofAPP_STATE and FRAMEWORK_STATE to complete the WHAT. Once the framework lazily creates the event handler, the event handler can process the event. Notice that the client is not redoing any work that the server has already done.
The DOM elements retain the event handlers for the lifetime of the element. Hydration eagerly creates all of the listeners. Therefore hydration requires allocating a memory on startup.
Resumable frameworks do not create the event handlers until after the event is triggered. Therefore, resumable frameworks will consume less memory than hydration. Furthermore, the resumable approach does not retain the event handler after execution. The event handler is released after its execution, returning the memory.
In a way releasing the memory is the opposite of hydration. It is as if the framework lazily hydrates a specific WHAT, executes it, and then dehydrates it. There is not much difference between the first and nth execution of the handler. Event handlers' lazy creation and release does not fit the hydration mental model.
Conclusion
Hydration is overhead because it duplicates work. The server builds up the WHERE and WHAT (APP_STATE and FRAMEWORK_STATE), but the information is discarded instead of being serialized for the client. The client then receives HTML that does not have sufficient information to rebuild the application. The lack of information forces the client to eagerly download the application and execute it to recover the WHERE and WHAT (APP_STATE and FRAMEWORK_STATE).
An alternative approach is resumability. Resumability focuses on transferring all of the information from the server to the client. The information contains WHERE and WHAT (APP_STATE and FRAMEWORK_STATE). The additional information allows the client to reason about the application without downloading the application code eagerly. Only a user interaction forces the client to download code to handle that specific interaction. The client is not duplicating any work from the server; therefore, there is no overhead.
To put this idea into practice, we built Qwik, a framework that is designed around resumabilty and achieves excellent startup performance. We're also excited to hear from you! Let's keep the conversations going and get better as a community at building faster web applications for our users.
— Love from the Builder.io team.
PS: Many thanks to Ryan Carniato, Rich Harris, Alex Patterson, Dylan Piercey, Alex Russell, Steve Sewell who provided constructive feedback for the article. ❤️
We know you have a few burning questions. That's why we've put together an FAQ to address them all.
Why coin a new term?
Is resumability just hydration after the event?
What are real world results like? Where can I see a site that uses a resumable strategy?
My framework knows how to do progressive and/or lazy hydration. Is that the same thing?
My framework knows how to create islands. Is that the same thing?
My framework knows how to serialize the state. Does it have overhead?
Is a component hydrated on first interaction?
How can I take advantage of resumability today?
Is there a delay on first interaction?
Can I use my React/Angular/Vue/Svelte components with Qwik?