For decades, developers have lived by a simple mantra: "Make it work, make it work right, make it work fast." This ordered priority has guided software development through multiple technological waves. As we enter the age of AI, these principles remain crucial but we need to evolve our thinking.
At Builder.io, we've developed our own mantra for building production-grade AI tools:
- Make it completely integrated.
- Make it reliable and predictable.
- Make it highly performant.
At Builder.io, we've just launched Visual Copilot 2.0, our next-generation AI-powered development environment that transforms Figma designs into production-ready code.
In this post, I'll share the engineering decisions and architectural approaches we took to build a production-grade AI system that delivers on these principles.

Just as a JIRA ticket alone isn't enough context for a developer to implement a feature properly, a simple prompt isn't enough for an AI to generate production-quality code. The reality is much more complex, requiring:
- Business context
- Design system specifications
- Component libraries
- Codebase knowledge
- API integrations
- Code style guidelines
The first principle in our AI tooling mantra is complete integration. Here's how we've implemented it:

We've built several core systems that ensure seamless integration with existing tools and workflows:
- Component mapping: A declarative syntax for mapping Figma components to React, Vue, or Angular components with 100% reliability
- DevTools CLI: Leverages TypeScript's compiler to extract and understand project patterns
- Mitosis: Our open-source compiler that transforms React-like components into multiple framework outputs
- Decision trees: Break down complex Figma designs into manageable chunks for LLM processing
- Advanced RAG: Retrieval-augmented generation system that helps understand how companies want their code structured and formatted, collecting data about coding patterns and preferences to ensure consistent output
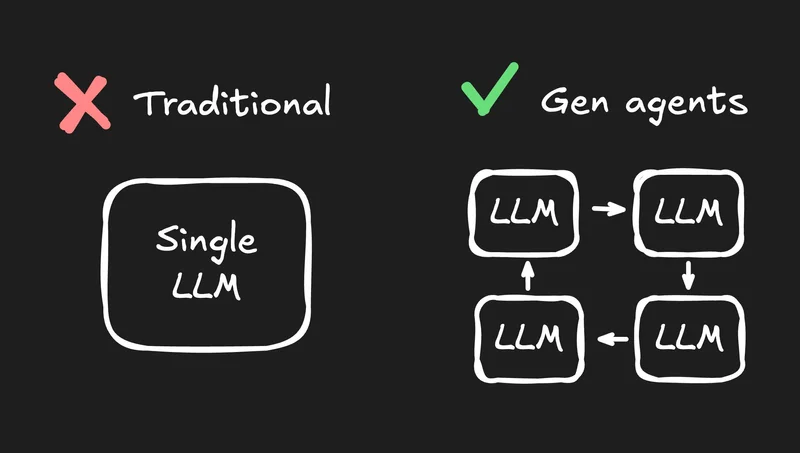
The second principle focuses on creating AI systems that developers can trust. We've achieved this through our Gen Agents architecture:
- Focus on specific tasks (animations, interactivity, data wiring)
- Operate with narrow context and specific goals
- Run in rapid feedback loops
- Can work in parallel
- Validate and iterate quickly
This approach significantly reduces hallucinations and increases reliability by breaking complex tasks into manageable, verifiable pieces.
Our third principle ensures that our AI tools maintain their utility at scale. Traditional AI implementations often suffer from:
- Large context windows
- Slow processing times
- Linear scaling with document size
- Increased hallucination risk with larger contexts
We've addressed these challenges through:
Instead of passing all context through an LLM, we've implemented a system of downstream and upstream models that can process input efficiently. These models intelligently filter and process only the essential parts that need LLM attention, dramatically reducing the processing overhead. We only delegate the key parts to the LLM, making the entire pipeline much more efficient.
When you make changes like renaming elements, our system can intelligently patch updates across the entire codebase without re-emitting unchanged code, styles, or other elements - making iterations significantly faster since most updates only require changing a small portion of the code.
The real impact of our performance optimizations becomes clear when you look at scaling. In traditional systems, as your document grows in complexity or size, the time to render and iterate grows linearly. Not only does this slow down development, but it also increases the chances of hallucinations due to larger context windows.
Our architecture maintains consistent performance regardless of project size. In our benchmarks:
- Initial generation takes around 8 seconds
- Updates complete in approximately 3 seconds
- These times remain stable whether you're working with a simple card component or an entire landing page
This stability is crucial for maintaining developer flow and ensuring our tools remain practical for real-world use, where projects often grow large and complex over time.
Our latest release, Visual Copilot 2.0, brings all these capabilities together in a powerful visual development environment. It allows teams to:
- Convert Figma designs to production-ready code
- Make real-time updates with AI assistance
- Connect to real data and APIs
- Generate interactive components
- Maintain consistent performance at scale
Signup and try Visual Copilot 2.0 today!
Building production-ready AI tools isn't just about having the latest LLM or the flashiest demos. It's about creating reliable, predictable systems that developers can trust and use efficiently. By combining deterministic systems with specialized AI models, we've created a tool that's not just powerful, but practical for everyday use.
The future of development tools lies not in replacing human expertise, but in augmenting it with AI in thoughtful, reliable ways. We're excited to see how teams use Visual Copilot 2.0 to build better products faster while maintaining the quality and reliability their users expect.



