Speculative Module Fetching: a Modern Approach to Faster App Interactivity
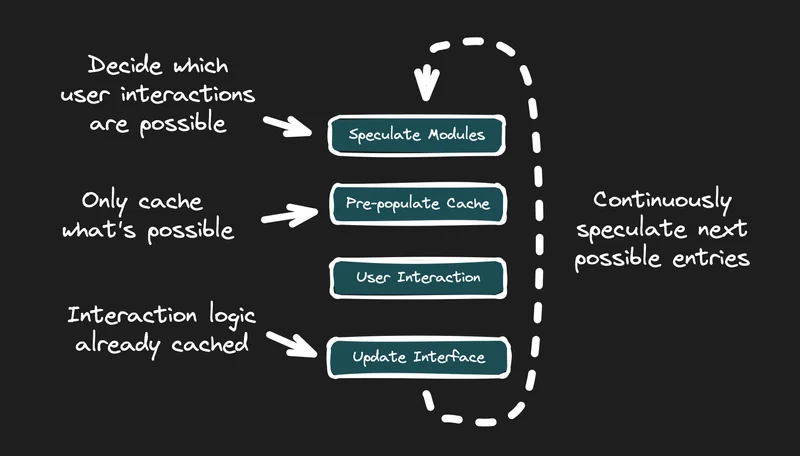
Speculative Module Fetching is an approach that optimizes app responsiveness by loading only the possible points of user interactivity based on the current state of the app. As the user interacts with the app, it continues to speculate and fetch the next possible modules.
Before we dive in, let's compare the differences between downloading a two-hour movie and streaming it. When you download a video file to your device, you can't start watching it until the download is complete. For a multiple gigabyte video file, this can take a while.
Thankfully, services like Netflix, Hulu, and YouTube are well aware of this issue. That's why they stream content to your devices. When you start playing the movie, you stream only the first few seconds.
As you watch the movie, the service continues to buffer the next few seconds you're about to watch. And if the user stops and never finishes streaming the movie, that's fine. It doesn't waste resources on the user's device or the service's network.
Qwik City applies the same streaming concept by anticipating which modules the user might interact with next, based on the content they are viewing.
Rather than loading modules on-demand (as known as lazy-loading), Qwik City pre-populates the cache ahead of time with modules the user may need. This also differs from prefetching, where often the entire application’s JavaScript is downloaded using main-thread resources.
Similar to video streaming, Qwik City fetches the next modules ahead of time in a background thread as the user continues to interact with the application. This allows the application to grow in size and complexity while still maintaining fast startup, interactivity, and responsiveness.
For instance, suppose that a page has a click listener on a button. When the page loads, the system ensures that the bundle for that click listener is downloaded and stored in the cache. When the user clicks the button and Qwik makes a request to the event listener's bundle, the bundle is already sitting in the cache, ready to execute.
To take it one step further, it’s similar to like a video game quest. Choose your own adventure. As the user navigates the app, the app will cache what’s needed next.
Since Qwik uses resumability, instead of hydration, the build creates many different entry points for the app, rather than a single main.js script.
The previous mindset has been that there’s only one script that starts an application. And even if there’s lazy-loading with dynamic imports and the </code> is added just before </body>, this initial script that contains the framework still has to run in order for the entire application to work.

With resumability, Qwik is able to continue an application from the state that it was when it left the server (either SSR or SSG).
Instead of a single entry that involves hydration to get up and running, there are many points at which the application can resume. In many cases, the app may never even need to start some parts or even the entire app.
Due to Qwik’s unique module extraction primitive and resumability, pages startup and become interactive extremely fast without requiring any JavaScript. The next question, however, is if JavaScript isn’t required, how does interactivity even work?
Traditional web development often resorts to prefetching and hydration, or a combination of both. Even though you may be lazy-loading per page, you still need the framework to hydrate the app. And when you require the framework in order for it to work, the user has a non-responsive app as the framework is downloading and hydrating. And for low-end mobile devices on real-world networks, this could be too long for the user to wait.
Qwik, on the other hand, does not use a traditional main-thread prefetching or lazy-loading approach, but rather takes advantage of service workers to execute Speculative Module Fetching.
Service workers are typically thought of as a way to make an application work offline. However, Qwik City takes advantage of the powerful features of service workers to provide Speculative module fetching and heavily caching modules on the user's device.
The goal is not to download the entire application (which users probably won’t interact with most of it anyways), but rather to use a service worker to dynamically download what is possible to execute at that moment. By not downloading the entire application, resources are freed up to only request the small parts of the app a user could use for what they have on their screen at that time.

An advantage of using a service worker is that it's also an extension of a worker, which runs in a background thread.
Web workers make it possible to run a script operation in a background thread separate from the main execution thread of a web application. The advantage of this is that laborious processing can be performed in a separate thread, allowing the main (usually the UI) thread to run without being blocked/slowed down.
By moving the downloading and caching logic to a service worker (which is a worker), we're able to essentially run the code in a background task, in order to not interfere with the main UI thread. By not interfering with the main UI we're able to help improve the performance of the application for end-users.
- Page HTML loads without any hydration or framework JavaScript.
- Main thread sends to the service worker all of the possible user interactions on that page at that time.
- Service worker receives a message from the main thread of all possible interactions.
- Service worker fetches modules it does not already have stored in the Cache API.
- When the user interacts with the app, dynamic imports pull from the pre-populated cache.
A network waterfall is when numerous requests happen one after another, like steps downstairs, rather than in parallel. Below is an exaggerated case of a less-than-ideal request waterfall.
A waterfall of network requests usually hurt performance because it increases the time until all modules are downloaded, rather than each module starting to download at the same time.
Below is an example with three modules: A, B and C. Module A imports B, and B imports C. The HTML document is what starts the waterfall by first requesting Module A.
In this example, when Module A is first requested, the browser has no idea that it should also start requesting Module B and C. It doesn't even know it needs to start requesting Module B, until AFTER Module A has finished downloading. Basically, the browser doesn't know ahead of time what it should start to request, until after each module has finished downloading.
However, because our service worker contains a module graph generated from the manifest at build time, we already know all of the modules which will be requested next. Qwik can even know which interactions the user will most likely use next with Real Metric Optimizations, but more on that later.
So when either user interaction or requesting a bundle happens, the worker thread initiates the request for all of the bundles that it already knows will be requested. This way, we drastically reduce the time it takes to request all bundles.

When Qwik requests a module, it uses the standardized dynamic import(). For example, let's say a user interaction happened, requiring Qwik to execute a dynamic import for /abc.js. The pseudo-code would look something like this:
What's important here is that Qwik itself has no knowledge of a caching strategy. It's simply making an HTTP request for a URL. However, because we've installed a service worker, and the service worker is intercepting requests, and the service worker is able to inspect the URL and say, "hey look, this is a request for /abc.js! This is one of our bundles! Let's first check to see if we already have this in the cache before we do an actual network request."
This is where the power of the service worker and cache API comes in! Qwik first pre-populates the cache for modules the user may soon request within another thread. And better yet, if it's already cached, then there's no need for the browser to do anything.
And remember, the service worker also knows which additional modules are imported by each module, so we can reduce the network waterfall by kicking off each request in parallel.
It may be possible to fire off duplicate requests for the same resource. For example, let's say we want to import module-a.js, and while that's being downloaded (which may take a short time or a very long time, we don't know), the user interacts with the app, which then decides to request and execute module-a.js. Browsers will often fire off a second request for the same URL, which makes matters worse.
The service worker approach can avoid this by identifying a request that is already in flight, waiting on the first request for module-a.js to finish, and then cloning it for the second request.
Only one network request will happen, even though numerous module imports may call for the same request/response.
One of the unique features of the Qwik Optimizer is its ability to provide a deep understanding of how an application works and how it can be best split apart. Unlike blindly lazy-loading entire chunks of code (usually split at the page level), the Optimizer can bundle at an extremely fine-grained level due to its module extraction primitive.
In the above example, the button cannot be changed, so no templating or core rendering code is necessary. When the button is clicked, the app console logs "Clicked,” which is all that needs to be fetched ahead of time. Even Qwik's core library is not required in this case.
Furthermore, when using signals, very little JavaScript is needed because only the specific DOM node within the app needs to be updated, rather than re-rendering the entire component tree as is common in other frameworks.
Most of Qwik's actual work is done at build-time, and its core feature is understanding that the click event code is not the component's rendering code. The above is a simple example, but this optimization can scale by minimizing the need to load most of the application's templates, interactions, and logic.
Bundlers do a good job concatenating JavaScript. But they lack the context of how the application will actually be used out in the real-world, by real-users, on production servers.
Since Qwik uses module extraction and resumability to create many fine-grained modules, it combines modules, which results in fewer requests. Instead of having one tiny module per interaction, Qwik can bundle them more efficiently.
However, to take it to next level, Qwik can also bundle and prioritize modules depending on how users actually run the application. For example, if users of a product page most commonly click the Add to Cart button, and change the order quantity, then the bundler knows to group those modules together, and to make it the first module to cache on page load.
But much more on Real Metric Optimizations feature later…
Building a massive application, but without a massive amount of JavaScript, is quite a challenge. This is where we’ll continue to research ways to improve efficiently requesting, caching and bundling Qwik’s modules.
If you want to know more about Qwik’s Speculative Module Fetch please take a look at our docs: